mm84321
Distinguished Member
- Joined
- Aug 2, 2009
- Messages
- 2,762
- Reaction score
- 7
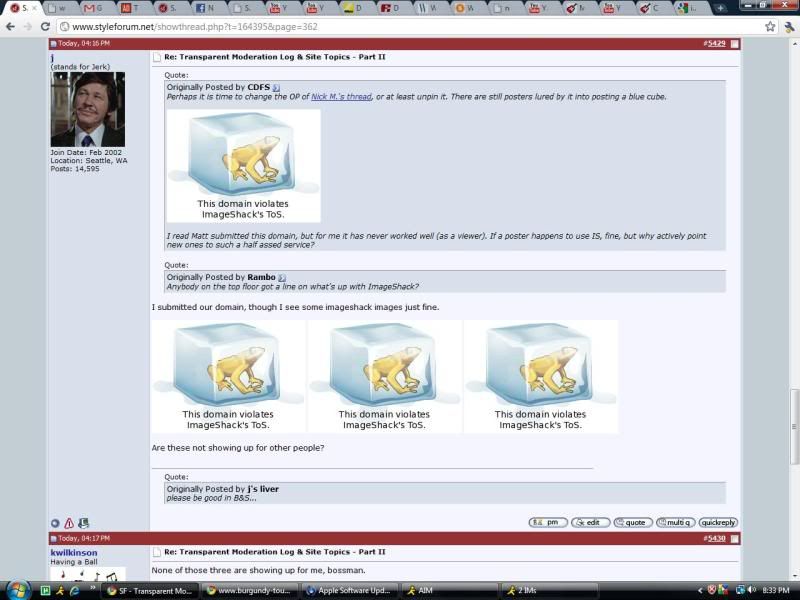
Another issue I thought of while pondering the idea is that many of those images are now dead -- imageshack or the original uploader pulled them. I don't know how imageshack would deal with thousands of failed HTTP requests.Originally Posted by deadly7
My original idea was to use a Perl script to connect to the database, run an SQL query on the posts field and then go every imageshack URL and wget them onto the SF server. As for saving them, I would [hope] vB lays its database out in a useful manner (eg: board, thread, post), which would make the naming/renaming schema easy.
It's rather unfortunate. Browsing through some old threads last night, it's a pity not being able to see the images that were originally posted.